Índice
|2022 |2021 |2019 |2018 |2017 |2016 |2015 |2014 |2013 |2012 |2011 |2010 |2009 |2008 |2007 |
2022
Michael Stonebraker: El Futuro de las Bases de Datos
Me llegó una notificación sobre una conferencia de Michael StoneBraker en el Postgres Build 2021 y teniendo en cuenta su papel como diseñador de una de las bases de datos más empleadas en el mundo, merece la pena oírlo. ¿Lo comentamos?
Leer más ➤2021

Darwin: Evolución de Unix
Cuando hablamos de GNU/Linux, hablamos de un sistemas operativo con núcleo monolítico creado en inspiración de MINIX, inspirado a su vez en Unix. Unix sin embargo es un sistema operativo con un micronúcleo que le confiere unas características específicas y Darwin es una de sus evoluciones mantenidas dentro de Apple, ¿sabías sus ventajas e inconvenientes?
Leer más ➤
El Infame Punto y Barra
En 1996 instalé la primera versión de GNU/Linux en mi PC, compilé un código en C y no pude ejecutarlo. No sabía el porqué. El fichero estaba ahí y al igual que en DOS con los ficheros de tipo exe parecía poder ejecutarse. Tiempo después me dijeron que debía escribir la ruta relativa o absoluta al fichero o agregar la ruta actual, el punto (.) dentro del PATH, ¿pero por qué?
Leer más ➤
NewSQL: ¿en qué consiste?
Cuando hablé de PACELC surgió un término curioso: NewSQL. A diferencia de NoSQL este movimiento no viene a eliminar el uso de SQL de los Sistemas Gestores de Base de Datos (SGDB) sino más bien a completarlo. ¿Sabes en qué consiste?
Leer más ➤
PACELC: Más allá de CAP
Revisando la información sobre el teorema CAP encontré un nuevo teorema llamado PACELC que viene a completar a CAP y que comienza a tenerse en cuenta dentro de sistemas de base de datos como CockroachDB, ¿conoces este nuevo teorema?
Leer más ➤
Falacias de Programación Distribuida
Programar en sistemas distribuidos es diferente a programar para solo un sistema. Algoritmos eficientes de forma secuencial pueden no serlo tanto cuando desarrollamos de forma distribuida, pero ¿qué hay de todo el código escrito tomando ciertos axiomas como completamente ciertos cuando no lo son?
Leer más ➤2019
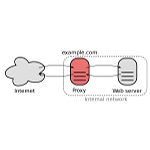
Proxy Inverso: Sistemas HTTP Heterogéneos
Los servidores cada vez más están compuestos de servicios y microservicios heterogéneos. Muchos de ellos incluso son conglomerados accesibles a través de subdominios pero los frontales y las direcciones IP por donde accedemos a estos servicios de forma pública son solo una. ¿Cómo conseguimos esto?
Leer más ➤2018

IMAP o POP3: ¿Cuál uso para el correo?
Cuando decidimos utilizar un cliente de correo en nuestro móvil o en nuestro ordenador y configuramos un proveedor poco corriente, uno que no tiene nuestro cliente de correo en una lista con un asistente para ayudarnos a configurarlo paso a paso siempre sucede que nos pregunta el acceso para leer los emails que nos llegan y hay que elegir entre estos dos protocolos: ¿usamos POP3 o IMAP?
Leer más ➤
HTTP/2 y HTTP/3: ¿Cómo funcionan?
Tiempo atrás hablámos sobre cómo funciona el sistema web. En ese momento me basé en las versiones del protocolo más extendidas: 1.0 y 1.1; pero hace tiempo que HTTP/2 está funcionando tanto en servidores como en navegadores y recientemente se está elaborando HTTP/3, ¿sabes qué ventajas nos proporcionarán?
Leer más ➤
IPv6: ¿Estamos preparados?
Hace unos días publiqué un juego de conceta cuatro en un servidor de Vultr. Daban una opción económica de publicar el servidor solo con IPv6 y decidí probar porque su implantación comenzó en 2011 (hace ya 7 años), ¿crees que nuestros ISP están preparados para IPv6?
Leer más ➤
PostgreSQL BDR: Cómo mantener un servicio
Recientemente cambié de proveedor de servidores de Hetzner a una mezcla entre Scaleway y DigitalOcean. La ventaja ha sido disponer de muchos servidores pequeños por la mitad del precio de uno grande pero, ¿cómo conseguir que una base de datos como PostgreSQL trabaje en multi-datacenter?
Leer más ➤
Fish Shell: La shell de los noventeros
Hace poco encontré por casualidad esta nueva shell: fish. Según su web y slogan es una consola de línea de comandos de los 90s. ¿Le echamos un vistazo?
Leer más ➤2017

Bragful: Un PHP escalable y confiable
PHP no ha evolucionado como otros lenguajes para cubrir la necesidad de sistemas reactivos puesta de moda y necesaria en los nuevos tiempos de la informática. Afortunadamente Bragful ha llegado para ayudar. ¿Quieres saber qué es y cómo funciona?
Leer más ➤
Yaws: Probando el Servidor Web de Erlang
En mis charlas sobre Erlang/OTP siempre hablo de lo bien que se comporta Yaws frente a otros servidores web en lo referente a carga. La cantidad de llamadas entrantes soportadas frente a otros sistemas, pero nunca me había animado a repetir el experimento de Joe Armstrong, ¿probamos un poco?
Leer más ➤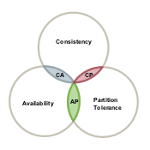
El Teorema CAP
De estas tres características: consistencia, disponibilidad y tolerancia a particiones, el teorema CAP nos dice que tan solo es posible seleccionar dos. Esta elección deben realizarla todos los sistemas que trabajan en cluster compartiendo información. En bases de datos cada sistema hace su propia elección, ¿sabrías decir cuáles eligieron los diseñadores de la base de datos que usas?
Leer más ➤
Redis 3.0 Cluster: Mayor Disponibilidad para Redis
El desarrollo de Redis ha sido dirigido siempre hacia la velocidad. Cada comando en la página de ayuda tiene la medida de la complejidad en base a poder medir rendimiento. Sorprende que finalmente hayan decidido lanzar la configuración en cluster pero, ¿qué ventajas y desventajas tiene?
Leer más ➤
¿Cómo funciona el Servidor de Nombres (DNS)?
Tras hablar hace tiempo del sistema web y del sistema de correo veo fundamental y complementario a estos abrir un nuevo cómo funciona para hablar del sistema de nombres (o DNS) que permite traducir nombres como altenwald.com en direcciones IP a través de una consulta a un servidor. ¿Sábes cómo funciona?
Leer más ➤
Scrapy: Gateando por Webs
Uno de los trabajos que he estado realizando últimamente es la captura de información de diversas webs (productos y artículos) a una base de datos. Al principio hacía pequeños scripts, pero esta vez quise probar algo más estructurado y profesional. Scrapy. ¿Sabes lo fácil que es hacer scraping de una web con él?
Leer más ➤
Introducción a Docker
Para mi Docker es a los administradores de sistemas como git es a los desarrolladores. Un sistema perfecto para mantener un control de cambios y versiones de máquinas. ¿Te interesa saber qué es Docker y cómo funciona?
Leer más ➤
Servidores: Ganado vs Mascotas
En la administración de sistemas aprendemos a poner nombre a los servidores. Es necesario para poder acceder a ellos no solo por una dirección IP sino también a través de un nombre que es más fácil de recordar y que permita a nuestros scripts una mayor abstracción. ¿Estos nombres deberían asignarse amistosamente como si fuesen mascotas o deberían ser secuenciales como se asigna al ganado?
Leer más ➤2016

Ansible: Automatización de otra Galaxia
Llevo años queriendo escribir sobre herramientas de automatización desde hace tiempo, el problema no es no haber encontrado tiempo sino considerar las herramientas de control de configuración o demasiado manuales (como Fabric) o demasiado dependientes de una estructura cliente/servidor... ¿En qué se diferencia Ansible?
Leer más ➤
VerneMQ: Internet de las Cosas (IoT) y Mensajería (IM)
Hace unos días una persona me preguntó, ¿cuál es el mejor sistema y protocolo para crear un chat para aplicaciones móviles? Le hablé de XMPP por supuesto, pero también de MQTT. Hace un par de años hice una comparativa entre estos protocolos y determiné que había mucho por hacer en MQTT como para tenerlo en cuenta. Sin embargo, útlimamente los contras sobre XMPP me hacen replantearlo.
Leer más ➤
Publicación y Subscripción en PostgreSQL
De aquí a un tiempo he encontrado muchas empresas solicitando integrar el sistema de Pub/Sub de Redis en su arquitectura para conseguir agregar capacidades de chat. ¿Sabías que esto mismo podía hacerse en PostgreSQL?
Leer más ➤2015

La Hora en Erlang
Cuando hablamos de Erlang y enumeramos sus características entre ellas aparece el tiempo real blando (soft realtime). Erlang se ejecuta en una máquina virtual que tiene una gestión de procesos, memoria y acceso a recursos, pero lo que no había citado hasta el momento es su capacidad para controlar los eventos horarios. Sí, tiene gestión horaria dentro de su máquina virtual también, ¿para qué?, ¿cómo funciona?
Leer más ➤
Virtualizando: Xen vs KVM
Uno de los últimos proyectos que he realizado últimamente ha tenido como punto fuerte y principal las estadísticas (usando graphite y collectd principalmente) y paravirtualización empleando Xen (a través de los servicios de Amazon). De pronto un problema de rendimiento. ¿Por qué un incremento en E/S eleva tanto el uso de la CPU en Xen?
Leer más ➤
Graphite: Monitorizando Servidores
En 2014 uno de los principales problemas que surgió en el proyecto que estuve realizando en Finlandia fue la poco o nada visualización que teníamos de los servidores, la carga de trabajo, los usuarios en cada momento del día, ... Estábamos ciegos. Cuando un sistema se caía, monit se encargaba de levantarlo pero, ¿por qué se caía?, ¿podemos adelantarnos o saber cuándo podría suceder?
Leer más ➤2014

¿Reinicio ahora?
De repente un servidor se apaga, se enciende la alarma en Nagios, nos preocupamos y al poco rato los mensajes de monit y por Skype una explicación: He visto que teníamos una versión comprometida de OpenSSL para el heartbleed, he actualizado y reiniciado; ¿y por qué has reiniciado?
Leer más ➤
Fabric: despliegues en cadena
El objetivo de cada programador es llevar a producción el código que escribe. En los tiempos que corren, este código se suele preparar para estar disponible para ejecutarse como servidor, dentro de un servidor o como paquete para descarga desde la nube. ¿Pero cómo podemos hacer que ese código llegue a estar preparado sin convertir esta tarea en épica?
Leer más ➤
MQTT vs XMPP
Una de las curiosidades de las aplicaciones de que dispone Facebook hasta la fecha es sus protocolos para el chat. Mientras que Whatsapp y la mayoría de sus competidores (salvo Telegram), emplean el protocolo XMPP, el chat de Facebook emplea el protocolo MQTT, ¿por qué?
Leer más ➤2013

Erlang: Volviendo a la Incrustación
A través de twitter me llega la noticia de que en la Erlang Factory de San Francisco se ha presentado una charla sobre La vuelta al incrustado (embedded) de Erlang. Esta vuelta se ha realizado de la mano de Erlang Solutions y su proyecto Erlang Embedded. La charla corrió a cargo de Omer Kilic. Se puede ver el vídeo en Youtube.
Leer más ➤
Erling: Erlang on Xen
Después de la noticia en la revista Forbes acerca de la computación en la nube y la solucion de Cloudozer llamada Erlang on Xen, se hace más patente la repercursión de Erlang en la evolución de la computación en la nube y sus siguientes pasos.
Leer más ➤
Elementary OS
Hace unos meses me pasaron este enlace de una nueva distribución de Linux llamada Elementary OS. Gracias José Luis Navarro por la info.
Me fascinó bastante que a diferencia de otras distribuciones que las que se cuidan aspectos de instalación y distribución, Elementary OS iba un poco más allá diseñando su propia interfaz de escritorio muy al estilo Gnome, su propio gestor de ficheros, editor de textos, calendario, navegador web, ... en esencia es un sistema ligero que integra la mayoría de aplicaciones que incluye cualquier otro sistema operativo.
Leer más ➤2012

SOA con XMPP
Al entrar en mi nueva empresa me topé con un cambio drástico en la forma en la que los elementos de la infraestructura se comunican entre sí. Para entenderlo mejor, mi compañero Iván me dejó el libro XMPP: The Definitive Guide, escrito por Peter Saint-Andre , Kevin Smith y Remko Tronçon.
Leer más ➤
eJabberd 3 y MongooseIM: dos puntos de vista
El proyecto ejabberd es de los más grandes y populares de los realizados en Erlang. Muchas empresas, con la salida de la web interactiva, la aparición cada vez más grande de sistemas de chat en la propia web, e incluso a través de dispositivos móviles, se ha propagado gracias al uso que han hecho empresas como Tuenti, Facebook, Whatsapp, Yuilop, etc. de esta herramienta.
Leer más ➤
Redis: NoSQL de alto rendimiento
Después de haber dado un repaso a Riak, MongoDB y Cassandra, ya era hora de hacer algo con Redis.
Leer más ➤
Websocket y Erlang
Hace un tiempo (ya unos años), escribí algo que había leído del blog de Joe Armstrong acerca de websocket, hoy retomo el tema después de leer un email de la lista de ErlAr, de un mensaje de Mariano Guerra en el que nos da estos datos sobre un banco de pruebas realizado con varias librerías, en varios lenguajes, sobre el uso de websocket:
Leer más ➤
Jingle: el paso a VoIP de Google
El protocolo XMPP se caracteriza porque se establece sobre una conexión TCP, sobre la que se comienza un documento XML que van completando las dos partes, tanto el cliente como el servidor, de modo que al finalizar la conexión (de forma correcta), se obtiene un documento único de todo lo transmitido entre las dos partes.
Leer más ➤
Cassandra: la NoSQL de Facebook
Tras haber visto Riak un poco más de cerca, ahora le toca el turno a Cassandra. Esta base de datos NoSQL fue desarrollada en el seno de Facebook, como una de sus 7 tecnologías clave. En 2008 fue donada a Apache y desde entonces su popularidad ha ido creciendo cada vez más.
Leer más ➤
Riak: Revisando y Practicando
Después de la introducción que hice ya hace unos meses sobre la teoría en la que se fundamenta esta base de datos, me he dispuesto a someterla a unas pruebas de funcionamiento, para así aprender a manejar de forma apropiada esta herramienta.
Leer más ➤
Redirigiendo tráfico
He estado revisando para cambiar el servidor a otro nuevo, con una versión limpia y actualizada de Debian (la nueva versión Squeeze), por lo que, toca migrarlo todo.
Leer más ➤2011

Túneles con SSH
Hace tiempo que empleo túneles para poder acceder a ciertos servicios inaccesibles desde Internet, o para agregar seguridad a un acceso determinado. Esto es posible gracias a los túneles que se pueden crear con la herramienta OpenSSH.
Leer más ➤
Cron: programando tareas
Una de las cosas que siempre me ha gustado de Unix, es lo que siempre reseña Eric S. Raymond a través de la archiconocida filosofía Unix: la interfaz universal son los flujos de texto; y eso posibilita que los comandos se puedan programar en el tiempo y realizar tareas no atendidas que nos faciliten la vida.
Leer más ➤
De MySQL a MariaDB
O del delfín a la foca, o de lo privado a lo público, ... mucho ha llovido desde que MySQL salió y con su versión 3.23 recorrieran el mundo instalándose de los primeros en soportar la mayoría de sitios web en Internet a través de la idea LAMP.
Leer más ➤
MongoDB: Base de Datos Heterogénea
Hace tiempo que tenía pendiente dar una vuelta a las base de datos NoSQL para mostrar un poco el cómo funcionan, qué se puede hacer con ellas y cómo se comportan en ciertas situaciones específicas.
Leer más ➤
Riak: Base de Datos sin SPOF
Dando una vuelta por Internet, buscando información sobre base de datos NoSQL, topé con una (u otra) hecha en Erlang/OTP, al igual que CouchDB, pero que se basa en las mismas directrices para lo que fue desarrollado Erlang/OTP. Esta base de datos es Riak.
Leer más ➤
Bundler: Despliega fácilmente Rails
Después de haber dado una vuelta por la versión estable de rails, he reparado en que, por defecto, se instala bundler y un fichero llamado Gemfile en la raiz de cada proyecto rails que se genera nuevo.
La verdad es que, en el momento que vi el fichero de Gemfile, queda clara la misión de dicho fichero, ya que viene con una colección básica de gemas que se suelen instalar de forma base cuando se trabaja con rails (out of the box) y unos comentarios de gemas que aconsejan para ciertos usos cotidianos (opcionales).
Leer más ➤
Apache: Módulo Status Server
El otro día me acerqué a ver qué hacía un compañero de trabajo (Fermín), ya que estábamos teniendo algún que otro problema con los servidores web, y veo que en su pantalla tiene una ventana abierta con los procesos internos que está gestionando Apache, así como información de memoria, el uso de los hilos disponibles, etc.
Le pregunté inmediatamente qué era esa pantalla, ya que me impresionó de sobremanera que una pantalla así pudiese estar disponible para los servidores web (hay mucho que indagar y descubrir aún en Apache y otros grandes servidores ;-).
Leer más ➤2010
FTS (I): Búsqueda de Texto Completo en PostgreSQL
Al final me dió por actualizar los PostgreSQL a la nueva versión 9.0, junto con el pgadmin3, y al entrar a la aplicación (versión 1.12.1) me encuentro que hay unos cuatro iconos nuevos: Configuraciones FTS, Diccionarios FTS, Analizadores FTS y Plantillas FTS. ¿y qué es todo esto?
Leer más ➤
Procesos en GNU/Linux
Me he dado cuenta de que, hace bastante tiempo que aprendí cómo se gestionan (sobre todo desde la consola) la creación, parada, paso a segundo plano y cambio de prioridad de los procesos de los sistemas tipo Unix, pero, que es algo no tan trivial para la gente que comienza a usar este tipo de entornos, y sobretodo los que vienen de sistemas con Windows.
Por ello, voy a explicar lo que son los procesos de este tipo de sistemas operativos (sobre todo orientándome en GNU/Linux).
Leer más ➤
¿Cómo funciona el sistema web?
Hace ya tiempo escribí una entrada parecida basándome en el sistema de correo, hoy el tema que nos ocupa es la web. El sistema web es el medio más usado por todos los usuarios de Internet, constituyéndose como el sistema asociado por defecto a la idea preconcebida que se tiene sobre Internet: páginas web.
Leer más ➤
Shell In A Box: Administración Remota en HTTP
La mayoría de los sistemas de tipo Unix tienen sistema de acceso vía consola a través de herramientas como telnet o SSH.
Estos elementos de conexión usan unos puertos específicos para la conexión, pero el primero no es nada seguro (todo se transmite en plano, tal y como se ve en pantalla, a través de la red) y el segundo requiere de la apertura de un puerto, que en muchas redes está filtrado o es inaccesible.
Leer más ➤
Permisos en GNU/Linux
Nota: Realmente, es la declaración de permisos en sistemas Unix, BSD, Solaris, GNU/Linux y derviados, pero pongo el título principal como GNU/Linux, porque realmente es el único entorno en el que doy fe de que todo lo que hay escrito en este artículo funciona al 100%.
El sistema GNU/Linux, al igual que su inspiración Minix, y la raíz de estos sistemas, Unix, se basan en ficheros. Todo es un fichero. Por ello, la seguridad de acceso a este tipo de información es muy importante.
Leer más ➤
Lógica de negocio en la base de datos
Desde mi punto de vista, esto puede suponer una locura total y una falta de forma en lo que respecta al uso de un almacén de datos visto como tal. No obstante, hay sistemas de base de datos que implementan una capa de negocio bastante interesante, donde otros sistemas solo dan una opción de scripting que da algo de miedo.
En postgresql, por ejemplo, el sistema de lenguajes que se pueden usar e implementar para la creación de funciones: PL/pgSQL, PL/Tcl, PL/Python, PL/Perl, PL/PHP, PL/Java, PL/Ruby, ...; todos ellos se pueden ver en la página de documentación de PostgreSQL.
Leer más ➤
NoSQL: sistemas de almacenamiento en lugar de bases de datos
Hace poco me topé con una definición que me causó un poco de desconcierto, no llegaba a entender bien el porqué había muchas empresas y profesionales que comenzaban a usar el NoSQL.
Leyendo el blog de dos ideas con referencia a un artículo que publicaron llamado NoSQL: el movimiento en contra de las bases de datos, se comenta una conferencia en la que grandes profesionales del sector de los sistemas, con necesidades de escalabilidad y alta capacidad de almacenaje, mencionaban sus soluciones NoSQL.
Leer más ➤
Pretty URLs
Muchas veces hemos visto las URL de algunos sitios que tienen, tras una interrogación de cierre (?) una hilera de valores con iguales (=) separados por ampersand (&). No obstante, hay otros muchos sitios que sus URLs, más específicamente sus URIs, son palabras en minúscula, con algunos guiones y números escasos, separados por barras inclinadas (/). Este último método es conocido con pretty urls.
Tener este tipo de URLs, o URIs en nuestro dominio, se puede hacer mediante la creación de directorios y especificando los ficheros dentro de los mismos que tengan los nombres (sin extensión) que queremos que se visualicen en la barra del navegador... pero no es nada útil y es complejo, sobre todo cuando se usan entornos como WordPress o similares, donde el contenido de la base de datos dicta lo que aparece en la página, y es totalmente dinámico.
Leer más ➤
El futuro de MySQL
Desde que MySQL fuese vendida a Sun Microsystems, ha habido bastante gente que ha visto con otros ojos el proyecto, mostrándose algo escépticos a que MySQL pudiera seguir siendo lo que venía siendo, una base de datos libre sin mayores pretensiones. Pero siendo Sun Microsystems una empresa que ha realizado mucho código para la comunidad, pero también ha guardado mucho otro de forma recelosa, teníamos nuestras dudas.
El problema real vino cuando Sun Microsystems fue adquirida por Oracle. Esta adquisición puso a MySQL en la duda de si seguiría siendo lo que es, o pasaría a ser otro producto más recortado en su versión comunitaria y ofrecido por un precio medio/alto a empresas que se lo puedan permitir. Como si de una versión light de Oracle DB se tratase.
Leer más ➤2009
La Regla de los Nueves
Esto es algo que aprendí, ahora hace ya unos 5 años, cuando comencé a instalar mi primer servicio de alta disponibilidad.
En un artículo sobre el tema, la alta disponibilidad, se decía que la disponibilidad de un servicio, servido únicamente por una máquina, normalmente es de un 90%, con lo que, a lo largo de un año (365 días) el servicio se ha mantenido en funcionamiento un máximo del 90%, aproximadamente, y ha tenido un tiempo de inactividad del 10% (más o menos unos 36 días).
Leer más ➤
Sistemas de Mensajes Encolados (MQ)
Hace poco me he encontrado con un problema. Tengo un entramado de servidores y comunicaciones entre cada uno de ellos. Cada servidor puede notificar, ya sea vía SOAP, HTTP, XMPP o mediante cualquier otro protocolo, un evento o una información a otro servidor del entramado, con lo que cada servidor se configura de una forma específica, con una serie de nombres de dominio o IPs.
El problema viene al querer aplicar escalabilidad al proyecto. Cuando no solo hay un equipo implicado, sino que existen dos o tres, los cuales hay que configurar bajo ciertas circunstancias.
Leer más ➤
Escalado de Ruby on Rails
Después de liberar el primer proyecto escrito en Ruby on Rails, cuando lo pasamos a producción, nos dimos cuenta de que el sistema funcionaba realmente lento. En algunos casos, incluso, no respondía, con lo que buscamos información por internet y vimos:
Leer más ➤
¿Cómo funciona el sistema de correo?
Esta es una pregunta que no todo el mundo se formula y, realmente, no es tan simple contestar. Quizás de todos los servicios de Internet, el sistema de correo es uno de los más complicados que existe. ¿Te has preguntado alguna vez cómo funciona?
Leer más ➤
MVCC: Control de Concurrencia para Múltiples Versiones de PostgreSQL
El sistema de base de datos PostgreSQL integra un sistema de control de concurrencia para múltiples versiones, en principio. Esto no es más que un sistema que se encarga de mantener copias sobre los datos de forma paralela, para acelerar el sistema de escritura de datos a disco duro, haciendo un control de concurrencia entre las distintas versiones que se van escribiendo.
Leer más ➤
CouchDB: REST y Base de datos documental
Tal y como comentaba en otro artículo anterior, el sistema REST permite un acceso a los datos basado en la mezcla entre localizaciones de elementos (URL) y verbos de HTTP para indicar lo que se desea hacer con ese elemento. Eso, agregando un almacén de datos que permita albergar elementos y otras características añadidas, nos dan como resultado CouchDB.
Leer más ➤
Debootstrap: Probar sin ensuciar
Desde hace tiempo, llevo usando esta herramienta para generar jaulas de modo que pueda probar nuevos sistemas, servidores y/o configuraciones, sin necesidad de desconfigurar mi sistema actual.
El sistema se basa en tener una copia exacta y nueva de un sistema operativo basado en Debian GNU/Linux, que se instala en un directorio específico de nuestro árbol de directorios. El comando que genera la jaula, que tiene el nombre de debootstrap, se encarga de realizar la instalación del sistema a partir del directorio solicitado y con las fuentes solicitadas, es decir, si queremos instalar un woody, sarge, etch, lenny... o un gutsy, hardy, ibex... pues solo tenemos que indicarlo, con la URL de donde conseguir los paquetes y listo.
PostgreSQL: Configuración de Acceso
Esto es algo que siempre me toca buscar en Internet, puesto que es algo que hago una vez cada tantos meses, y siempre se me olvida de cómo empezar, así que, para tener la chuleta a mano, he decidido escribir esta entrada que, además de servirme ahora, seguro que me servirá en el futuro para cuando configure más servidores de este tipo.
Leer más ➤
SQL Server vía ODBC en Debian Etch
Casi a punto de asistir a la liberación de lenny (la versión 5.0 de Debian), seguimos viendo que con etch, aún, tenemos lo suficiente para tirar perfectamente, y sin agregar paquetes de backport.
En este caso, voy a explicar como instalar y usar SQL Server vía ODBC desde cualquier aplicación en GNU/Linux, como pueden ser programas Java, Perl, PHP, Ruby...
Leer más ➤
Bases de Datos Relacionales: SQLite, MySQL y PostgreSQL
Sobre los SGBD, cabe destacar, entre los que son libres, estos tres motores, de los cuales, dos de ellos son sistemas servidores y gestores de base de datos relacionales (MySQL y PostgreSQL) y otro es tan solo un motor embebido para aplicaciones monousuario o de muy baja carga (SQLite).
Los sistemas libres han hecho gala del uso de LAMP (Linux, Apache, MySQL y PHP) para el desarrollo rápido de webs. Estos sistemas son fáciles, rápidos y cómodos para usuarios nóveles, dan mucho control sobre el desarrollo y permiten, gracias a la cantidad de proyectos ya desarrollados, tener a disposición Foros, Bitácoras, CMS, ERP, CRM y muchos más tipos de webs.
Leer más ➤2008
Servidor de hora en GNU/Linux
En las redes internas de la mayoría de empresas, se sucede la necesidad, muchas veces, de tener sincronización horaria en las máquinas para mejorar el rendimiento y la calidad de los datos a almacenar, de cara a anotaciones y lanzamiento de tareas programadas.
La sincronización horaria es completamente posible de llevar, simplemente, instalando un servidor de hora NTP dentro de nuestra red, para que nos haga de servidor de sincronización.
Leer más ➤2007
Redes en Linux
Este artículo es bastante antiguo. Forma parte de un curso de redes para GNU/Linux escrito en 2007. El documento en PDF puede ser descargado a través de este enlace.
Leer más ➤
Asterisk: Configuración de Zapata
Este artículo es bastante antiguo. Forma parte de una forma de configurar los interfaces analógicos de telecomunicaciones para Asterisk escrito en 2007. El documento en PDF puede ser descargado a través de este enlace.
Leer más ➤
Software empaquetado y listo para usar
Los paquetes son una forma de distribuir software compilado para una arquitectura concreta. En Windows se distribuyen en comprimidos autoejecutables que autoconfiguran el entorno y en GNU/Linux también, pero de forma más controlada.
Los paquetes de GNU/Linux tienen que cumplir la especificación de ordenación de ficheros que establece la distribución en concreto donde se va a instalar la aplicación, así pues, nos encontramos a este respecto con dos grandes variantes: RPM y DEB.
Leer más ➤Categorías
Etiquetas
- programación (111)
- desarrollo de software (79)
- erlang (75)
- opinión (37)
- noticia (36)
- libros (28)
- servidores (26)
- desarrollo web (24)
- base de datos (24)
- administración de sistemas (23)
- php (22)
- desarrollo ágil (22)
- empresa (21)
- otp (20)
- ruby (19)
- ingeniería de negocio (18)
- elixir (18)
- desarrollo profesional (16)
- redes (16)
- seguridad (14)