Índice
|2021 |2016 |2015 |2014 |2013 |2012 |2011 |2010 |2009 |2008 |2007 |
2021
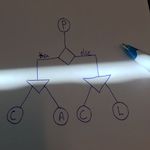
PACELC: Más allá de CAP
Revisando la información sobre el teorema CAP encontré un nuevo teorema llamado PACELC que viene a completar a CAP y que comienza a tenerse en cuenta dentro de sistemas de base de datos como CockroachDB, ¿conoces este nuevo teorema?
Leer más ➤
Falacias de Programación Distribuida
Programar en sistemas distribuidos es diferente a programar para solo un sistema. Algoritmos eficientes de forma secuencial pueden no serlo tanto cuando desarrollamos de forma distribuida, pero ¿qué hay de todo el código escrito tomando ciertos axiomas como completamente ciertos cuando no lo son?
Leer más ➤2016

Ansible: Automatización de otra Galaxia
Llevo años queriendo escribir sobre herramientas de automatización desde hace tiempo, el problema no es no haber encontrado tiempo sino considerar las herramientas de control de configuración o demasiado manuales (como Fabric) o demasiado dependientes de una estructura cliente/servidor... ¿En qué se diferencia Ansible?
Leer más ➤Vagrant: Recursos en Red
Hace dos años escribí sobre Vagrant. Desde entonces se ha convertido en mi herramienta favorita para el desarrollo de software. No solo permite construir una máquina a medida del entorno donde correrá la aplicación, también permite la construcción de un entorno de trabajo incluso publicando las máquinas en la red local. ¿Has pensado en tener tu propio CPD en tu red local?
Leer más ➤
VerneMQ: Internet de las Cosas (IoT) y Mensajería (IM)
Hace unos días una persona me preguntó, ¿cuál es el mejor sistema y protocolo para crear un chat para aplicaciones móviles? Le hablé de XMPP por supuesto, pero también de MQTT. Hace un par de años hice una comparativa entre estos protocolos y determiné que había mucho por hacer en MQTT como para tenerlo en cuenta. Sin embargo, útlimamente los contras sobre XMPP me hacen replantearlo.
Leer más ➤2015
Graphite: Monitorizando Servidores
En 2014 uno de los principales problemas que surgió en el proyecto que estuve realizando en Finlandia fue la poco o nada visualización que teníamos de los servidores, la carga de trabajo, los usuarios en cada momento del día, ... Estábamos ciegos. Cuando un sistema se caía, monit se encargaba de levantarlo pero, ¿por qué se caía?, ¿podemos adelantarnos o saber cuándo podría suceder?
Leer más ➤
RabbitMQ In Action
Este año he comenzado leyendo. Al igual que muchos, me he propuesto aprender nuevos conocimientos y los elegidos para este mes de enero han sido RabbitMQ, Elixir y FreeBSD. El primero lo hago de la mano de Álvaro Videla y Jason J.W. Williams, a través de su libro RabbitMQ In Action. La primera pregunta a resolver: ¿Para qué necesitamos un sistema de encolado de mensajes?
Leer más ➤2014

Piensa en el !11
Hace unos días Marga estaba enfrascada en el desarrollo de una solución para web basada en JSON-RPC y surgió la frase, por parte del cliente (Nothmann Research): piensa en el !11. Cuando me lo comentó no lo entendí de primeras. El factorial de 11, ¿por qué?
Leer más ➤
Fabric: despliegues en cadena
El objetivo de cada programador es llevar a producción el código que escribe. En los tiempos que corren, este código se suele preparar para estar disponible para ejecutarse como servidor, dentro de un servidor o como paquete para descarga desde la nube. ¿Pero cómo podemos hacer que ese código llegue a estar preparado sin convertir esta tarea en épica?
Leer más ➤2013

Vagrant: construye tu entorno de trabajo
De siempre me he dado cuenta de que muchas veces intento modificar algún proyecto, algún entorno que requiere de un entorno de trabajo muy específico y me paso unas cuantas horas rehaciendo ese entorno en mi PC a través de técnicas como rvm, kerl o más llanamente con el update-alternatives de Debian. Pero, ¿cómo podría tener un entorno de trabajo desde cero y en muy poco tiempo funcionando?
Leer más ➤
SOA 2.0: XMPP como ESB para el IoT
Hace tiempo escribí una entrada sobre la posibilidad de utilizar XMPP como elemento para SOA (service oriented arquitecture, arquitectura orientada al servicio), hoy vuelvo de nuevo con la idea y amplio un poco más gracias a este artículo (en inglés) que me ha llamado la atención sobre el hecho, ya no solo como sistema SOA, sino también como ESB (enterprise service bus, bús de servicio empresarial), para mantener comunicación entre todos los recursos de un sistema de la información.
Leer más ➤2012

cowboy: servidor pequeño, rápido y modular
Hace poco que le llevo siguiendo la pista a este framework para desarrollo en Erlang. cowboy se ha convertido, para mi, en una referencia a nivel de sistemas de inversión de control en Erlang, ya que son los únicos que he visto, hasta el momento (aparte de ciertas partes de código dentro de ejabberd) que usan los behaviours para extender funcionalidad.
2011

Cron: programando tareas
Una de las cosas que siempre me ha gustado de Unix, es lo que siempre reseña Eric S. Raymond a través de la archiconocida filosofía Unix: la interfaz universal son los flujos de texto; y eso posibilita que los comandos se puedan programar en el tiempo y realizar tareas no atendidas que nos faciliten la vida.
Leer más ➤
¡Hacking ético liberado!
Hoy leo, del propio autor, Carlos Tori, una noticia en la lista de NNL Newsletter sobre Seguridad y Redes, en la que dice, literalmente:
Leer más ➤Estimados, he decidido liberar la obra para que los interesados puedan disfrutarla de modo libre y distribuirla.
Espero que la disfruten, saludos.

Apache: Módulo Status Server
El otro día me acerqué a ver qué hacía un compañero de trabajo (Fermín), ya que estábamos teniendo algún que otro problema con los servidores web, y veo que en su pantalla tiene una ventana abierta con los procesos internos que está gestionando Apache, así como información de memoria, el uso de los hilos disponibles, etc.
Le pregunté inmediatamente qué era esa pantalla, ya que me impresionó de sobremanera que una pantalla así pudiese estar disponible para los servidores web (hay mucho que indagar y descubrir aún en Apache y otros grandes servidores ;-).
Leer más ➤2010
Shell In A Box: Administración Remota en HTTP
La mayoría de los sistemas de tipo Unix tienen sistema de acceso vía consola a través de herramientas como telnet o SSH.
Estos elementos de conexión usan unos puertos específicos para la conexión, pero el primero no es nada seguro (todo se transmite en plano, tal y como se ve en pantalla, a través de la red) y el segundo requiere de la apertura de un puerto, que en muchas redes está filtrado o es inaccesible.
Leer más ➤
La importancia de la actualización
Desde hace años, me vengo encontrando con sistemas instalados que hay que mantener o sobre los que hay que desarrollar, que son instalaciones de hace 5 ó 7 años. Estas instalaciones suelen ser máquinas con RedHat 9, RedHat EL 2, 3 ó 4, o Fedora Core 2 ó 3. En esos años RedHat estaba muy metido en el entorno empresarial y Fedora Core fue una respuesta libre (totalmente) a la desaparición de RedHat Desktop.
El caso es que la empresa y la comunidad que soportan ambas distribuciones (incluso distros comos OpenSuSE o SuSE, Mandriva y otras similares) les pasa que desarrollan versiones de forma bastante rápida (una o dos al año), con lo que, pasando 5 años, pueden haber salido unas 10 versiones posteriores del producto.
Leer más ➤2009
La Regla de los Nueves
Esto es algo que aprendí, ahora hace ya unos 5 años, cuando comencé a instalar mi primer servicio de alta disponibilidad.
En un artículo sobre el tema, la alta disponibilidad, se decía que la disponibilidad de un servicio, servido únicamente por una máquina, normalmente es de un 90%, con lo que, a lo largo de un año (365 días) el servicio se ha mantenido en funcionamiento un máximo del 90%, aproximadamente, y ha tenido un tiempo de inactividad del 10% (más o menos unos 36 días).
Leer más ➤
Sistemas de Mensajes Encolados (MQ)
Hace poco me he encontrado con un problema. Tengo un entramado de servidores y comunicaciones entre cada uno de ellos. Cada servidor puede notificar, ya sea vía SOAP, HTTP, XMPP o mediante cualquier otro protocolo, un evento o una información a otro servidor del entramado, con lo que cada servidor se configura de una forma específica, con una serie de nombres de dominio o IPs.
El problema viene al querer aplicar escalabilidad al proyecto. Cuando no solo hay un equipo implicado, sino que existen dos o tres, los cuales hay que configurar bajo ciertas circunstancias.
Leer más ➤
Escalado de Ruby on Rails
Después de liberar el primer proyecto escrito en Ruby on Rails, cuando lo pasamos a producción, nos dimos cuenta de que el sistema funcionaba realmente lento. En algunos casos, incluso, no respondía, con lo que buscamos información por internet y vimos:
Leer más ➤
MVCC: Control de Concurrencia para Múltiples Versiones de PostgreSQL
El sistema de base de datos PostgreSQL integra un sistema de control de concurrencia para múltiples versiones, en principio. Esto no es más que un sistema que se encarga de mantener copias sobre los datos de forma paralela, para acelerar el sistema de escritura de datos a disco duro, haciendo un control de concurrencia entre las distintas versiones que se van escribiendo.
Leer más ➤
Debootstrap: Probar sin ensuciar
Desde hace tiempo, llevo usando esta herramienta para generar jaulas de modo que pueda probar nuevos sistemas, servidores y/o configuraciones, sin necesidad de desconfigurar mi sistema actual.
El sistema se basa en tener una copia exacta y nueva de un sistema operativo basado en Debian GNU/Linux, que se instala en un directorio específico de nuestro árbol de directorios. El comando que genera la jaula, que tiene el nombre de debootstrap, se encarga de realizar la instalación del sistema a partir del directorio solicitado y con las fuentes solicitadas, es decir, si queremos instalar un woody, sarge, etch, lenny... o un gutsy, hardy, ibex... pues solo tenemos que indicarlo, con la URL de donde conseguir los paquetes y listo.
PostgreSQL: Configuración de Acceso
Esto es algo que siempre me toca buscar en Internet, puesto que es algo que hago una vez cada tantos meses, y siempre se me olvida de cómo empezar, así que, para tener la chuleta a mano, he decidido escribir esta entrada que, además de servirme ahora, seguro que me servirá en el futuro para cuando configure más servidores de este tipo.
Leer más ➤
SQL Server vía ODBC en Debian Etch
Casi a punto de asistir a la liberación de lenny (la versión 5.0 de Debian), seguimos viendo que con etch, aún, tenemos lo suficiente para tirar perfectamente, y sin agregar paquetes de backport.
En este caso, voy a explicar como instalar y usar SQL Server vía ODBC desde cualquier aplicación en GNU/Linux, como pueden ser programas Java, Perl, PHP, Ruby...
Leer más ➤2008
Servidor de hora en GNU/Linux
En las redes internas de la mayoría de empresas, se sucede la necesidad, muchas veces, de tener sincronización horaria en las máquinas para mejorar el rendimiento y la calidad de los datos a almacenar, de cara a anotaciones y lanzamiento de tareas programadas.
La sincronización horaria es completamente posible de llevar, simplemente, instalando un servidor de hora NTP dentro de nuestra red, para que nos haga de servidor de sincronización.
Leer más ➤2007
Asterisk: Configuración de Zapata
Este artículo es bastante antiguo. Forma parte de una forma de configurar los interfaces analógicos de telecomunicaciones para Asterisk escrito en 2007. El documento en PDF puede ser descargado a través de este enlace.
Leer más ➤Categorías
Etiquetas
- programación (111)
- desarrollo de software (79)
- erlang (75)
- opinión (37)
- noticia (36)
- libros (28)
- servidores (26)
- desarrollo web (24)
- base de datos (24)
- administración de sistemas (23)
- php (22)
- desarrollo ágil (22)
- empresa (21)
- otp (20)
- ruby (19)
- ingeniería de negocio (18)
- elixir (18)
- desarrollo profesional (16)
- redes (16)
- seguridad (14)