Índice
|2021 |2017 |2016 |2012 |2011 |2010 |2009 |
2021

NewSQL: ¿en qué consiste?
Cuando hablé de PACELC surgió un término curioso: NewSQL. A diferencia de NoSQL este movimiento no viene a eliminar el uso de SQL de los Sistemas Gestores de Base de Datos (SGDB) sino más bien a completarlo. ¿Sabes en qué consiste?
Leer más ➤2017
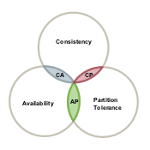
El Teorema CAP
De estas tres características: consistencia, disponibilidad y tolerancia a particiones, el teorema CAP nos dice que tan solo es posible seleccionar dos. Esta elección deben realizarla todos los sistemas que trabajan en cluster compartiendo información. En bases de datos cada sistema hace su propia elección, ¿sabrías decir cuáles eligieron los diseñadores de la base de datos que usas?
Leer más ➤
Redis 3.0 Cluster: Mayor Disponibilidad para Redis
El desarrollo de Redis ha sido dirigido siempre hacia la velocidad. Cada comando en la página de ayuda tiene la medida de la complejidad en base a poder medir rendimiento. Sorprende que finalmente hayan decidido lanzar la configuración en cluster pero, ¿qué ventajas y desventajas tiene?
Leer más ➤2016

Publicación y Subscripción en PostgreSQL
De aquí a un tiempo he encontrado muchas empresas solicitando integrar el sistema de Pub/Sub de Redis en su arquitectura para conseguir agregar capacidades de chat. ¿Sabías que esto mismo podía hacerse en PostgreSQL?
Leer más ➤2012

Redis: NoSQL de alto rendimiento
Después de haber dado un repaso a Riak, MongoDB y Cassandra, ya era hora de hacer algo con Redis.
Leer más ➤
UUID: Identificador Único Universal
Últimamente, cada más sistemas, y cada más sitios emplean algo llamado UUID, cuyas siglas vienen a decir: Universally Unique ID; aunque suene algo arrogante, el cálculo de un UUID casi que podríamos decir que garantiza el que sea único. Es más, su grado de colisión es tan bajo que si lo colocásemos como identificador de clave primaria de una tabla que alberga elementos recogidos aleatoriamente de otras tablas de bases de datos de todo el mundo, que hayan empleado este tipo de dato, garantizamos que no habrá repetidos.
Suena excitante, pero...
Leer más ➤
Cassandra: la NoSQL de Facebook
Tras haber visto Riak un poco más de cerca, ahora le toca el turno a Cassandra. Esta base de datos NoSQL fue desarrollada en el seno de Facebook, como una de sus 7 tecnologías clave. En 2008 fue donada a Apache y desde entonces su popularidad ha ido creciendo cada vez más.
Leer más ➤
Riak: Revisando y Practicando
Después de la introducción que hice ya hace unos meses sobre la teoría en la que se fundamenta esta base de datos, me he dispuesto a someterla a unas pruebas de funcionamiento, para así aprender a manejar de forma apropiada esta herramienta.
Leer más ➤2011

NewSQL: dos vías para mejorar SQL
Últimamente hay muchos medios (como SDJournal) que van haciendo eco de una nueva versión, según algunos más fácil, de SQL.
Según vemos en la página oficial del proyecto, NewSQL dispone a día de hoy de dos posibles gramáticas a implementar. Una de ellas está basada en la Java Database (JDB) y otra sería la evolución propia de SQL (SQL II, o S2). Aún no se ha decidido qué versión será la empleada como newSQL, por lo que, podemos decir que es un proyecto a futuro y no hay implementación real de momento.
Leer más ➤
De MySQL a MariaDB
O del delfín a la foca, o de lo privado a lo público, ... mucho ha llovido desde que MySQL salió y con su versión 3.23 recorrieran el mundo instalándose de los primeros en soportar la mayoría de sitios web en Internet a través de la idea LAMP.
Leer más ➤
MongoDB: Base de Datos Heterogénea
Hace tiempo que tenía pendiente dar una vuelta a las base de datos NoSQL para mostrar un poco el cómo funcionan, qué se puede hacer con ellas y cómo se comportan en ciertas situaciones específicas.
Leer más ➤
South: Migraciones en Django
Cuando escribí el artículo sobre Django, fui bastante positivo con respecto al sistema de llevar los modelos a la base de datos, ya que, según parecía, el sistema propuesto por syncdb era automágico, pero realmente, lo único que se encarga de realizar es la creación de nuevos modelos que estén en el fichero de models.py.
Riak: Base de Datos sin SPOF
Dando una vuelta por Internet, buscando información sobre base de datos NoSQL, topé con una (u otra) hecha en Erlang/OTP, al igual que CouchDB, pero que se basa en las mismas directrices para lo que fue desarrollado Erlang/OTP. Esta base de datos es Riak.
Leer más ➤2010

FTS (I): Búsqueda de Texto Completo en PostgreSQL
Al final me dió por actualizar los PostgreSQL a la nueva versión 9.0, junto con el pgadmin3, y al entrar a la aplicación (versión 1.12.1) me encuentro que hay unos cuatro iconos nuevos: Configuraciones FTS, Diccionarios FTS, Analizadores FTS y Plantillas FTS. ¿y qué es todo esto?
Leer más ➤
ETL: Revisando el Software
Hace ya más de un año que escribí una entrada sobre ETL, donde comentaba los principios que lo fundan y algún que otro software disponible para realizar ETL. Revisando la entrada, me he dado cuenta de que el software que entonces encontré, ha cambiado bastante, incluso uno de ellos ha desaparecido como tal.
Leer más ➤
Lógica de negocio en la base de datos
Desde mi punto de vista, esto puede suponer una locura total y una falta de forma en lo que respecta al uso de un almacén de datos visto como tal. No obstante, hay sistemas de base de datos que implementan una capa de negocio bastante interesante, donde otros sistemas solo dan una opción de scripting que da algo de miedo.
En postgresql, por ejemplo, el sistema de lenguajes que se pueden usar e implementar para la creación de funciones: PL/pgSQL, PL/Tcl, PL/Python, PL/Perl, PL/PHP, PL/Java, PL/Ruby, ...; todos ellos se pueden ver en la página de documentación de PostgreSQL.
Leer más ➤
NoSQL: sistemas de almacenamiento en lugar de bases de datos
Hace poco me topé con una definición que me causó un poco de desconcierto, no llegaba a entender bien el porqué había muchas empresas y profesionales que comenzaban a usar el NoSQL.
Leyendo el blog de dos ideas con referencia a un artículo que publicaron llamado NoSQL: el movimiento en contra de las bases de datos, se comenta una conferencia en la que grandes profesionales del sector de los sistemas, con necesidades de escalabilidad y alta capacidad de almacenaje, mencionaban sus soluciones NoSQL.
Leer más ➤
El futuro de MySQL
Desde que MySQL fuese vendida a Sun Microsystems, ha habido bastante gente que ha visto con otros ojos el proyecto, mostrándose algo escépticos a que MySQL pudiera seguir siendo lo que venía siendo, una base de datos libre sin mayores pretensiones. Pero siendo Sun Microsystems una empresa que ha realizado mucho código para la comunidad, pero también ha guardado mucho otro de forma recelosa, teníamos nuestras dudas.
El problema real vino cuando Sun Microsystems fue adquirida por Oracle. Esta adquisición puso a MySQL en la duda de si seguiría siendo lo que es, o pasaría a ser otro producto más recortado en su versión comunitaria y ofrecido por un precio medio/alto a empresas que se lo puedan permitir. Como si de una versión light de Oracle DB se tratase.
Leer más ➤2009
MVCC: Control de Concurrencia para Múltiples Versiones de PostgreSQL
El sistema de base de datos PostgreSQL integra un sistema de control de concurrencia para múltiples versiones, en principio. Esto no es más que un sistema que se encarga de mantener copias sobre los datos de forma paralela, para acelerar el sistema de escritura de datos a disco duro, haciendo un control de concurrencia entre las distintas versiones que se van escribiendo.
Leer más ➤
ETL: Extracción, Transformación y Carga
Este término, ETL, se acuña a la mayoría de transformaciones de datos que deben de realizar empresas para compatibilizar sus datos con los de sus proveedores y/o clientes.
Leer más ➤
CouchDB: REST y Base de datos documental
Tal y como comentaba en otro artículo anterior, el sistema REST permite un acceso a los datos basado en la mezcla entre localizaciones de elementos (URL) y verbos de HTTP para indicar lo que se desea hacer con ese elemento. Eso, agregando un almacén de datos que permita albergar elementos y otras características añadidas, nos dan como resultado CouchDB.
Leer más ➤
PostgreSQL: Configuración de Acceso
Esto es algo que siempre me toca buscar en Internet, puesto que es algo que hago una vez cada tantos meses, y siempre se me olvida de cómo empezar, así que, para tener la chuleta a mano, he decidido escribir esta entrada que, además de servirme ahora, seguro que me servirá en el futuro para cuando configure más servidores de este tipo.
Leer más ➤
SQL Server vía ODBC en Debian Etch
Casi a punto de asistir a la liberación de lenny (la versión 5.0 de Debian), seguimos viendo que con etch, aún, tenemos lo suficiente para tirar perfectamente, y sin agregar paquetes de backport.
En este caso, voy a explicar como instalar y usar SQL Server vía ODBC desde cualquier aplicación en GNU/Linux, como pueden ser programas Java, Perl, PHP, Ruby...
Leer más ➤
Bases de Datos Relacionales: SQLite, MySQL y PostgreSQL
Sobre los SGBD, cabe destacar, entre los que son libres, estos tres motores, de los cuales, dos de ellos son sistemas servidores y gestores de base de datos relacionales (MySQL y PostgreSQL) y otro es tan solo un motor embebido para aplicaciones monousuario o de muy baja carga (SQLite).
Los sistemas libres han hecho gala del uso de LAMP (Linux, Apache, MySQL y PHP) para el desarrollo rápido de webs. Estos sistemas son fáciles, rápidos y cómodos para usuarios nóveles, dan mucho control sobre el desarrollo y permiten, gracias a la cantidad de proyectos ya desarrollados, tener a disposición Foros, Bitácoras, CMS, ERP, CRM y muchos más tipos de webs.
Leer más ➤Categorías
Etiquetas
- programación (111)
- desarrollo de software (79)
- erlang (75)
- opinión (37)
- noticia (36)
- libros (28)
- servidores (26)
- administración de sistemas (24)
- desarrollo web (24)
- base de datos (24)
- php (22)
- desarrollo ágil (22)
- empresa (21)
- otp (20)
- ruby (19)
- ingeniería de negocio (18)
- elixir (18)
- desarrollo profesional (16)
- redes (16)
- seguridad (15)