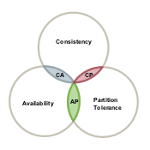
De estas tres características: consistencia, disponibilidad y tolerancia a particiones, el teorema CAP nos dice que tan solo es posible seleccionar dos. Esta elección deben realizarla todos los sistemas que trabajan en cluster compartiendo información. En bases de datos cada sistema hace su propia elección, ¿sabrías decir cuáles eligieron los diseñadores de la base de datos que usas?
Actualización 26/05/2021: el teorema CAP quedó un poco incompleto y con el tiempo han surgido otros estudios que lo completan y dan información complementaria basados en la implementación de sistemas de bases de datos distribuidos. Puedes leer sobre PACELC aquí.
Uno de los problemas cuando diseñamos un sistema para estar en la nube es la escalabilidad. Un sistema escalable normalmente debe poder crecer para aceptar cada vez más peticiones y permitir al sistema seguir funcionando de forma fluida. Incrementar el número de servidores web cuando estos son stateless no es un gran problema e incluso muchos sitios permiten la configuración rápida de un balanceador de carga para soportar este esquema.
El mayor problema viene cuando necesitamos escalar un sistema statefull. Estos sistemas contienen información y esta información debe ser accesible siempre desde cualquier punto. Cuando solo hay un servidor esto es simple. Cuando escalamos y disponemos de más de un servidor entonces esto se complica.
No hace mucho comenzaron a aparcer sistemas cluster para base de datos como MariaDB Galera Cluster o PostgreSQL XL que también han tenido que elegir entre estas opciones. Vamos a repasarlas.
Origen
Pero antes un poco de historia. El teorema tal y como nos dice la Wikipedia nació en el año 2000 de manos del doctor Eric A. Brewer como conjetura. No fue hasta el año 2002 cuando se demostró y publicó por Seth Gilbert y Nancy Lynch del MIT convirtiéndola en teorema.
Tolerancia a particiones
Mucho se ha hablado sobre este tema. Hay quien considera que este elemento no es negociable y debe estar entre las opciones e incluso que este elemento no debería incluirse directamente en las opciones y deberían ser tan solo dos.
El motivo es simple. Si tenemos un sistema que depende de varios servidores y esos servidores necesitan información, pensar en un sistema que no sea tolerante a particiones es creer en el mito de que la red es confiable.
No solo debemos pensar en nuestros sistemas para soportar una posible desconexión de los otros elementos sino también en el caso de que esa conexión reaparezca de nuevo. Cómo lidiar con los datos que han podido ser modificados de forma diferente en ambas partes. Ante esta situación dependerá qué otra opción hayamos seleccionado.
No obstante y obviamente hay antiguos sistemas no escalables que se basan en la elección de CA eliminando P como son los sistemas de base de datos sin replicación en una sola máquina. Pueden estar disponibles e incluso con sistemas de alta disponibilidad para tener un respaldo y ser consistentes porque la información está solo en un punto, pero no pueden lidiar con una pérdida de conexión de red.
Consistencia
Esta es la más elegida por sistemas dependientes de la información que no pueden permitirse un error. Por ejemplo los sistemas bancarios para la realización de transferencias. La consistencia de los datos está por encima de la disponibilidad.
Es preferible que el sistema no esté disponible en un momento dado a obtener diferentes versiones del mismo dato provocando pérdidas de información (o dinero en este caso).
La elección CP por tanto es la elegida en sistemas bancarios y por sistemas como Couchbase, MongoDB, HBase o Redis. No obstante recordemos que si instalamos Redis 3 en modo cluster (tal y como hablamos en otro post) estaremos eligiendo AP en lugar de CP.
Disponibilidad
La disponibilidad es la piedra angular de muchos sistemas que se basan en estar siempre ahí y no importa que la información eventualmente sea errónea pues se puede corregir más tarde.
Sistemas como los de mensajería se basan en esto (como WhatsApp o Slack por ejemplo). Un sistema de mensajería puede reorganizar los mensajes cuando se recupera de una partición de red sin problemas mientras se mantiene disponible para poder enviar nuevos mensajes.
La elección AP por tanto es la elegida en sistemas de la nube para estar siempre disponibles y por sistemas como CouchDB, Cassandra, Riak.
Estos sistemas se basan en la premisa de mantener una consistencia eventual con posibilidad de corregir la información en cualquier momento para mantener siempre la versión correcta con el tiempo.
Conclusiones
Depende de cada caso y puedo asegurar que hay miles de casos y miles de sistemas de base de datos. Algunos de ellos los hemos repasado en este blog de forma más o menos profunda. Quedan otros muchos que habrá que ir repasando.
¿Qué opinas del teorema? ¿Has necesitado decidir entre los elementos? ¿Cuál sacrificaste? ¿Necesitas más ayuda en relación con escalabilidad? ¡Déjanos un comentario!
