
Dando una vuelta por Internet, buscando información sobre base de datos NoSQL, topé con una (u otra) hecha en Erlang/OTP, al igual que CouchDB, pero que se basa en las mismas directrices para lo que fue desarrollado Erlang/OTP. Esta base de datos es Riak.
Actualización 16/09/2011: se me olvidó comentar que SPOF significa, según sus siglas, Single Point Of Failure, algo así como el punto único de fallo. Se refiere a cuando un sistema, aún teniendo bastante redundancia, tiene un punto único, en la red, en el software o en alguna parte del sistema que, fallando, deja sin servicio a todo.
Como la mayoría de software realizado por empresas y que se adentran en el software libre, Riak tiene dos versiones, una Open Source (que es completa y funcional) y otra Enterprise (que agrega commodities -o facilidades- tales como una interfaz de administración).
La base de datos Riak está basada en el documento escrito por Amazon sobre el sistema de almacenamiento Dynamo, el cual se basa en un sistema de alta disponibilidad, con estructura de almacenamiento del par clave-valor y distribuido. Este documento ha sido seguido, además, por Cassandra (la base de datos de Facebook, liberada y acogida en el seno de la Fundación Apache, y que ha sido implementada desde entonces por Digg, Twitter, Reddit, Rackspace, etc.) y por Voldemort (la base de datos de LinkedIn).
Características principales
Riak, además de seguir las bases de Dynamo, ha agregado otras características propias a la lista, quedando (visto en su página web oficial) la siguiente lista de características a destacar:
- Escalabilidad: la escalabilidad con Riak es lineal, predecible y de coste efectivo. Agregar nuevas máquinas no significa tener una avalancha de de peticiones que ponga en peligro la efectividad del sistema. Se pueden ir agregando o eliminando máquinas sin mayor problema, y sin que suponga una carga excesiva para el sistema base.
- Tolerancia a fallos: el cluster soporta o admite fallos en nodos aislados, o incluso en partes del cluster, está preparado para no perder datos ante este tipo de fallos. El sistema ha sido diseñado con fallos de máquinas e interrupciones de servicio de red como norma, no como excepción.
- Alta disponibilidad: para alta disponibilidad el sistema debe de estar disponible, no solo para lecturas, sino también para escrituras. La arquitectura de share-nothing (nada compartido) hace que cada nodo en el cluster esté habilitado para realizar lecturas y escrituras, por lo que, la alta disponibilidad está garantizada.
- Replicación: dependiendo de las necesidades, Riak se puede configurar para replicar entre múltiples clusters iguales o diseñar uno o más clusters como solo-lectura o backup. Cada nodo en el cluster puede responder a las peticiones de lecutra/escritura, y el evento de replicación asegura que todos los clusters sean actualizados. Los algoritmos se ejecutan en cada nodo asegurando la consistencia de datos.
En base al teorema CAP del Dr. Eric Brewer, las tres propiedades deseadas de un sistema distribuido son: consistencia, disponibilidad y partición (tolerancia a fallos). El teorema establece que puedes solo puedes tener dos de las tres propiedades en cada momento. Riak se enfoca en Disponibilidad y Partición. Esta elección pone a Riak en el campo de la consistencia eventual. Sin embargo, la ventana para consistencia eventual es en términos de milisegundos, lo que es suficiente para la mayoría de aplicaciones.
¿Cómo funciona?
No me quiero extender mucho, ya que esta información está disponible (aunque en inglés) en la propia web de Riak, en Concepts, así que resumiré un poco.
El almacén de datos se realiza en base a el par clave-valor, es lo que podríamos llamar una base de datos hash. No obstante, la clave se compone de bucket y key, que son como en Erlang el módulo y la función, o en Java el paquete y la clase. El conjunto bucket/key es la unidad de organización única que puede emplearse.
El sistema admite también el uso de enlaces (links). Esto quiere decir que el contenido de un bucket/key, puede ser un contenido o un enlace a otro bucket/key que tenga su propio contenido. Algo así como el enlace simbólico en los sistemas de ficheros de tipo Unix.
Además, el contenido, puede ir estructurado en forma de metadatos, es decir, como las cabeceras de los mensajes HTTP, para disponer de arrays asociativos (hash) dentro del contenido.
Uso de diferentes backends. En la versión 0.12, Bitcask se estableció como backend para Riak, pero hay más, aquí ponemos un listado de los disponibles:
- Bitcask: simple pero potente almacenaje de pares clave-valor. Es de baja latencia y alto rendimiento.
- DETS / ETS: tablas incorporadas en Erlang para el almacenamiento de información.
- Erlang Balanced Trees (gb_trees): sistema de árbol balanceado. Rápido para leer, pero algo lento para escribir.
- Innostore: basado en el engine InnoDB de MySQL. Debido a restricciones de licencia, se proporciona por separado.
Cada cluster que se configura de Riak, consta de los siguientes elementos:
- Nodos: nodos físicos, o máquinas, de las que se compone el cluster.
- Nodos Virtuales: nodos virtuales (o vnodes) que corren en cada máquina. Cada máquina física puede contener uno o varios nodos virtuales.
- Particiones: cada cluster Riak tiene un entero de 160-bits dividido en particiones ecuánimes. Cada vnode reclamará una partición del anillo.
Cada nodo en el cluster es responsable del 1/(número total de nodos físicos) del anillo. Puedes determinar el número de vnodes en cada nodo calculando el (número de particiones)/(número de nodos). Por ejemplo, un anillo con 32 particiones, compuesto por cuatro nodos físicos, tendrá aproximadamente ocho vnodos por nodo. Esta configuración es representada por el siguiente diagrama:
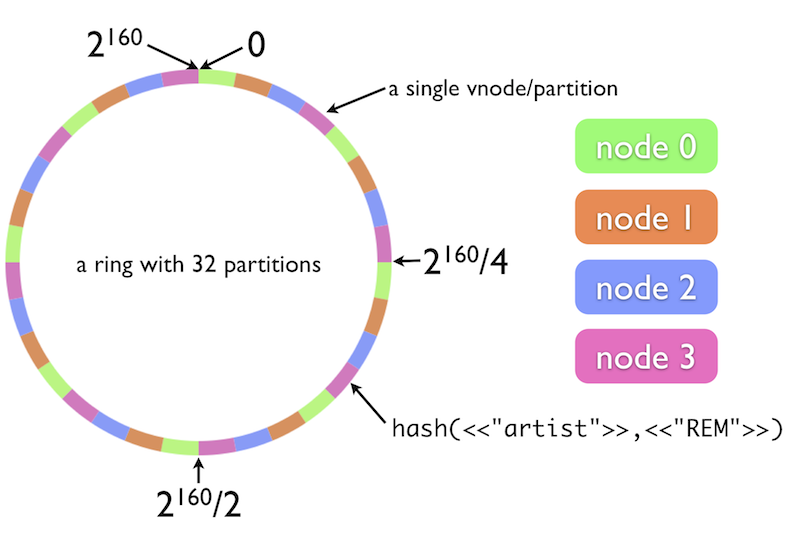
Riak está diseñado para ser un sistema distribuido, cuantos más nodos haya en el sistema, más rápido funcionará.
No hay nodo maestro, todos los nodos en Riak son iguales. Cada nodo es completamente capaz de servir cualquier petición de cliente. Esto es posible debido a la forma en la que Riak usa la consistencia de hash para distribuir datos a través del cluster, que se realiza a través de un gossip protocol.
Sobre la replicación
Riak controla tantas réplicas como datos son mantenidos a través de una configuración llamada n-valor. Este valor tiene una configuración por defecto en cada nodo pero puede ser sobreescrito por cada bucket. Los objetos de Riak heredan el n-valor de su bucket padre. Todos los nodos en el mismo cluster deben de acordar y usar el mismo n-valor.
Por ejemplo, aquí hay una representación de que sucede cuando n-valor es 3 (esta es la configuración por defecto). Cuando almacenas el dato en el bucket con un n-valor de tres, el dato se replicará a tres particiones separadas del anillo.
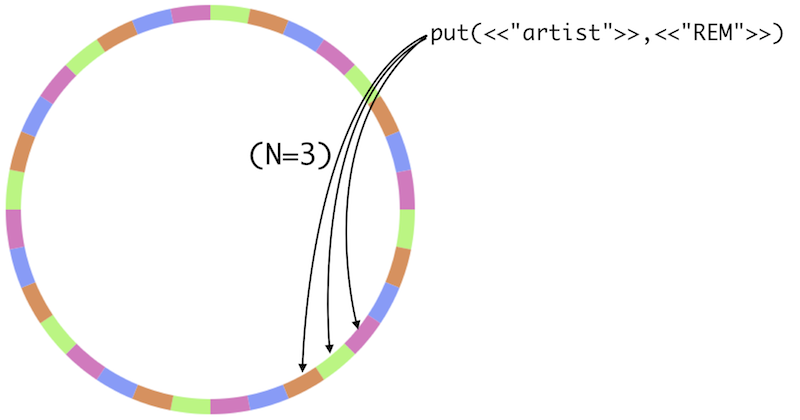
Y cuando un nodo falla o se agrega otro nodo, ¿qué sucede?
Riak usa una técnica llamada hinted handoff, para compensar el cluster en el momento que un nodo falla. Los vecinos del nodo fallido tomarán relevo y realizarán el trabajo de ese nodo permitiendo al cluster trabajar de forma normal. Esto puede considerarse una forma de auto-curación.
Si se agrega un nodo nuevo, en cambio, se rebalancean los datos.
Algunas pegas... siempre las hay
Primero, los buckets que usan un conjunto de propiedades no estandar forzarán a Riak a enviar vía gossip más datos a través del cluster. Los datos adicionales pueden ralentizar el proceso. Segundo, algunos backends, como Innostore, almacenan cada bucket como una entidad separada. Esto puede causar que nos quedemos sin recursos tales como manejadores de ficheros. Estas restricciones de recursos pueden no impactar al rendimiento, pero representarán otro límite en el máximo número de buckets a gestionar.
Conclusiones
A nivel teórico, todo bien, parece. Habrá que realizar un banco de pruebas y ver qué tal va el sistema. De momento, me he quedado sin tiempo (del que había planificado) para escribir este artículo, por lo que, dejo las pruebas para la siguiente parte... que entraremos de lleno en la práctica.
